Can we train models to play poker competitively online?
The traditional way for a computer to play Poker is to use a CFR (counterfactual regret minimization) solver, which will find a Nash equilibria in two-player zero-sum games. In multiplayer settings, CFR still tends to converge to good solutions, but loses its theoretical guarantee.
Critically, I’m not looking to learn an unexploitable equilibrium strategy. The variant of poker I’m interested in is anonymous fast-fold poker, where the players are shuffled after every hand and have no consistent identity between hands. That makes it very hard to exploit opposing players’ individual tendencies, but very easy to play highly profitable (but highly exploitable) strategies.
For example, suppose you three-bet every hand in a traditional game of poker. Very quickly, your opponents would realize that you must be three-betting with garbage, and would call more to exploit you. In fast-fold (variously called “zoom”, “zone”, etc.), if the player pool over-folds to three-bets, you might very well make money three-betting every hand. Your opponents have no way of knowing what % of the last 100 hands you have three-bet.
So our goal is to write a program which maximally profits from the population tendencies of zoom/zone player pools. The player pools have hundreds of players, so we can safely assume that the population tendencies will be roughly fixed.
Compute
I did this project in 2018 on my trusty steed, a 1080-Ti with a whopping 11Gi of VRAM and 11 teraflops of fp32 performance. (For those keeping track at home: this is approximately 1e4 times less compute than the 144 fp4 petaflops supplied by a 8xB200 node.)
(Board, Hole) Representations
There are a lot of important parts of poker to learn. The most basic is how the cards and board interact. We could build a bunch of manual features like draws_until_straight, which indicates how many draws are required from the current cards on the board until you can build a straight. I would rather have the network learn which features of boards and cards are useful, by training it on a surrogate objective. [0]
The most natural surrogate is equity estimation. Given a (partial) board and a two hole cards, we train the network to predict the equity of each of 1326 hands the opponent might hold. This network has 133 inputs; each card is encoded as rank + suit one-hot vectors (19 wide), with two private hole cards and between three and five community cards. It has 1326 outputs, corresponding to the percentage equity which our private cards have against each of the 1326 possible opponent cards. In practice, we do not penalize the network for its predictions on the 245-336 combinations which are impossible (e.g. opponent can not have 7c7h when 7h is on the board.)
We use BatchNorm and Dropout between layers, as was standard at the time, and train to minimize MSE.
SimpleEquityModel:
133 = (5 board cards + 2 hole cards) * (14 ranks + 5 suits)
-> Linear(133, 800) -> ReLU -> BatchNorm -> Dropout(0.1)
-> Linear(800, 400) -> ReLU -> BatchNorm -> Dropout(0.1)
-> Linear(400, 200) -> ReLU -> BatchNorm -> Dropout(0.1)
-> Linear(200, 100) -> ReLU -> BatchNorm -> Dropout(0.1)
-> Linear(100, 1326)
I wrote a Go script to generate 500k sample (hole, community) pairs, computed their true equity values, and saved this dataset to disk (OneHoldPartialBoard.csv) . Then, I trained this network for 20 epochs to roughly 0.0011 validation MSE, or about 3.3 percentage points of equity RMSE. I then clipped the last linear layer, to use the 100-wide representation as an input to future models.
Reference: poker-ml/Partial Board One Hole One Equity.ipynb
Data
It turns out you can buy tens of millions of poker hand history online for cheap. The traditional use of this data is to learn information about your competitors, like what percentage of the time CoolCard55 folds. Our use will be to train models.
The data have the following format:
PokerStars Hand #156624936552: Hold'em No Limit ($0.05/$0.10 USD) - 2016/07/30 4:59:02 ET
Table 'Shenzhen' 9-max Seat #3 is the button
Seat 3: Hero ($10.05 in chips)
Seat 8: Alpha242 ($10.89 in chips)
Hero: posts small blind $0.05
Alpha242: posts big blind $0.10
*** HOLE CARDS ***
Dealt to Hero [6h 7h]
Hero: raises $0.10 to $0.20
Alpha242: calls $0.10
*** FLOP *** [5s Jd Jc]
Alpha242: checks
Hero: bets $0.20
Alpha242: raises $0.51 to $0.71
Hero: calls $0.51
*** TURN *** [5s Jd Jc] [2s]
Alpha242: bets $1
Hero: raises $1.60 to $2.60
Alpha242: folds
Uncalled bet ($1.60) returned to Hero
Hero collected $3.65 from pot
Hero: doesn't show hand
*** SUMMARY ***
Total pot $3.82 | Rake $0.17
Board [5s Jd Jc 2s]
Seat 3: Hero (button) (small blind) collected ($3.65)
Seat 8: Alpha242 (big blind) folded on the Turn
The main issue is that these hands only show the hole cards when players show down (notice in the example: no hole cards!). So although there are many hand-histories where the players show down AA, there are very few where they show down 72o, because those hands are almost always folded before the flop. This biased dataset is one of the core challenges of this project.
Luckily, we have an additional constraint: players are dealt each of the 1326 possible poker hands with equal probability.
So although in ten thousand hand histories, we never see a player show down 72o, we can infer that the she must have folded those hands quite early.
(todo: how do we flatten this into vectors)
We ingest the text files and then flatten each hand into a sequence of decision rows. A hand-history parser first turns the raw text into a normalized event stream: metadata, seats/stacks, board updates, actions, payouts, and any showdown cards. Then a CSV exporter replays that event stream and emits one row immediately before each non-blind action. Each row has the public state at that point: the acting player’s position, stack, pot size, amount to call, players alive, players left to act, blind sizes, street, and board cards. It also includes the action that is then observed (fold, call, or raise) and the raise size.
Oracle
We now train a model, the OracleLSTM, which answers the following question: given the public history of a hand, what distribution should I assign over the 1326 possible private card combos?
In other words, suppose I give the history:
Player 1: Raise 3bb.
Player 2: Re-raise 10bb.
Player 3: Fold.
Player 1: Call.
Flop: 5h7sJc.
Player 1: Check.
Player 2: Bet 8bb.
Player 1: Fold.
What distribution of hands was player 1 was holding? We evaluate
JJ => 0.03% (would not have folded top set postflop)
72o => 0.08% (would not have raised preflop)
KQs => 1.5% (history makes sense; KQs is 0.9% of all hands, so 1.5% is a 1.5x likelihood ratio)
Probably not JJ, since they would not have folded top set postflop. Probably not 72o, since they would not have bet that hand preflop. It must have been strong enough to call a four-bet before the flop, but weak enough to fold after the flop. Maybe hands like KQs? This is exactly what good human poker players think about as they play. OracleLSTM learns to make these kinds of inferences.
Architecturally, the model works in two parts. We encode the public history of the hand with a BiLSTM (4 layers, hidden dimension 25). It outputs a 50-wide vector, which we then duplicate across 1326 rows (one per potential hand). Separately, we run the SimpleEquityModel all 1326 possible (private, community) tuples, which outputs a 1326x100 vector.
We then run a classic FF network 1326 times on that 150 wide input. That FF network is trying to predict, independently for each potential hand, how compatible the public action history is with that hand.
Finally, take a softmax over the 1326 logits, to get a distribution over the 1326 potential hands.
We also take a loss over the batch, where we sum the predictions for each hole card. Over the 1024 hands in each batch, we penalize the network for how far the distribution is from uniform. Without this second loss term, the network would never predict 72o, since players almost never show-down 72o. We know that they must be dealt it, and so we must allocate its probability mass to hands where the players fold early. (In those cases, since the hole cards are unknown, there is no prediction loss term.)
This network has 7.5M total parameters, and we train it for 3 epochs on 10 million decisions. (Note that each hand history expands to many rows, since we estimate a distribution after every action and not just the terminal action.)
The Oracle does not guess exact hole cards, which would be nearly impossible. Instead, it moves probability mass toward hands that were consistent with the betting line. A uniform guess over all 1,326 hands would give the true hand about 0.075% probability, corresponding to an NLL of about 7.19. The Oracle’s validation NLL was about 5.41, meaning it assigned the true hand about 0.45% probability on average, roughly six times better than random. Its ranking metric guesses the true hand in the top 13% of candidate hands on average.
Is this any good? Consider a player under-the-gun who folds approximately 85% of hands. The perfect oracle output for “Player 1 folds” is a uniform distribution over 1127 hands, which has a NLL of approximately 7.03 (or 6.77 when merged with the 15% that continue). So a model with an NLL of 5.41 has clearly learned something.
Action Models
We now build a model which can take an action. Recall that our dataset has very few examples of players playing 72o, but our policy model must nevertheless know how to play it. To bridge this gap, we run the Oracle on hands where the player folded, and then sample a representative pair of private hole cards. In this way, we generate synthetic samples where the policy model learns how to play weak hands properly, despite their enormous underrepresentation in the training set.
The inputs to this model are:
- A 150-wide representation from
OracleLSTMof each active opponent. - The 100-wide representation of the board texture and how it interacts with our private cards from
SimpleEquityModel - The raw game information (hole cards, board, stack sizes, pot size, sequence of all previous actions, etc)
We process the variable number of opponents with another BiLSTM, which returns an 848-wide representation of the opponent configuration. We concat another 88 features from the current player, state, etc, and run those 936 features through an MLP with hidden size 936 -> 331 -> 339 -> 245 -> 897 -> 4.
The four outputs are: fold_logit, call_logit, raise_logit, raise_size_scalar.
We use bayesian optimization to choose hyperparameters for this model (hence the weird numbers). We end up with the following performance, nicely improving as our sample count goes up.
740k samples: 70.7%
80k samples: 66%
24k samples: 63.5%
2k samples: 42.6%
Ideally we would train this on many more samples, but 740k samples already took all night on my 1080-Ti.
You can see the oracle and the action model interacting in the diagram below. Each row is one decision point: the first three heatmaps show how the current range supports fold, call, and raise, the fourth panel shows the aggregate action probabilities, and the final heatmap is the posterior hand range after the observed action.
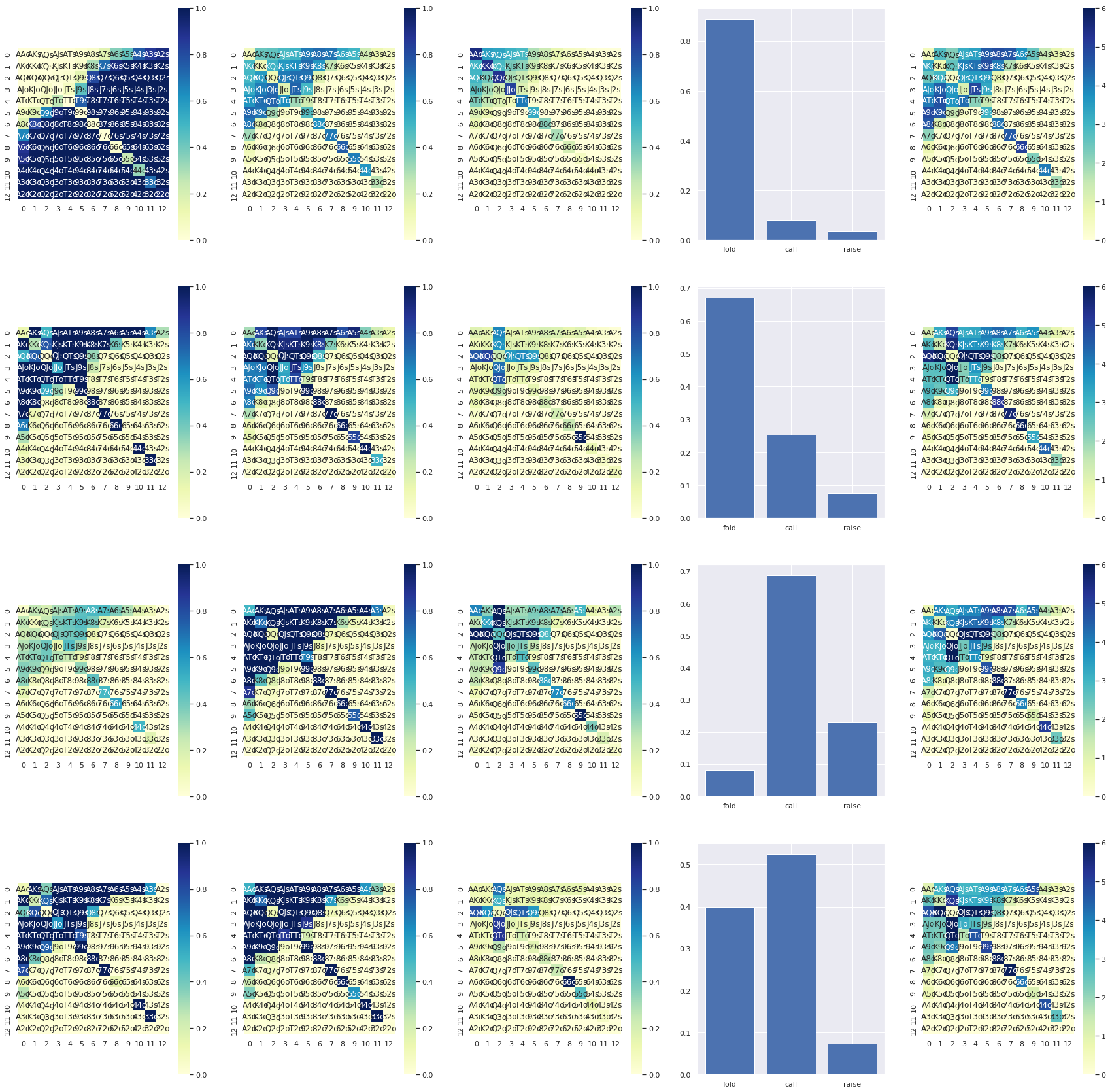
SFT on Players
Now, we have rich representations for both the board, and also for our model of other players. Can we use these representations to learn to imitate a specific (winning) player?
The most profitable player in our dataset on a bb-per-100 basis is named saevm. He won 10.6bb per hundred hands, on a sample of 128k hands, at 0.02 stakes. Even factoring in a correction from the winner’s curse, this is an astounding win rate.
One simple strategy is to train a action predictor on his hands. Recall: we mostly have hand histories where we know he has strong hands, plus a bunch of histories where he folded, but we don’t know which hole cards he folded. We can use the Oracle to sample potential hands, so that our policy network understands how it ought to play 72o, and other hands which rarely make it to showdown.
This sounds like a good plan, but in practice, when I played it at the tables, it did not work well. I’m not exactly sure why; my best guess is that there’s not enough data in our sample to learn the subtleties of what makes this player so profitable. Recall, we have 128k total hands from this player, and in perhaps 10% we know which cards he held.
Improving with PPO
Even if we don’t have enough data on great players, as long as we can correctly model an average player, we can use RL to improve against them. In particular, we will post-train that model of saevm with proximal policy optimization, playing in an environment against other simulated players. As long as our simulation of the average player has high enough fidelity, we can uncover profitable exploits automatically with reinforcement learning.
This has a similar shape to AlphaGo, which was recent at the time. We start by training on strong human examples, then eventually move to full RL when we saturate imitation learning.
We start by creating a poker environment. The five other players are controlled by the base action-prediction model. Our player is controlled by the PPO policy. Note that the opponents do not evolve; the purpose is not to find a general equilibrium for players playing together, but to exploit the (fixed) population tendencies of fast-fold poker rooms.
The PPO model has two parts: an actor and a critic. The actor chooses actions. The critic estimates how good the current state is, so that after a rollout we can ask: did this action do better or worse than expected?
The actor sees only legal decision-time information: our hole cards, the public board, stack sizes, pot size, betting history, position, and so on. It uses the same poker representation machinery as the imitation models: learned embeddings, equity features, and an LSTM over prior actions.
We keep the action space small and discrete: fold, call, raise half pot, raise full pot.
The critic gets one extra advantage: privileged simulation information. Since we are training inside our own engine, the critic can see all players’ hole cards and the future board runout. The actor does not get this information, so the deployed policy is still legal. But the critic can use it to produce a cleaner training signal. This is an asymmetric actor-critic setup: fair actor, cheating critic.
The training loop looks like this:
- simulate many hands against frozen population opponents
- record states, actions, log probabilities, rewards, and value estimates
- compute discounted returns
- compute GAE advantages
- optimize clipped PPO objective + value loss + entropy bonus
With hyperparameters:
batch_size: 8096 simulated environments
gamma: 0.995
tau: 0.94
ppo_clip: 0.2
opt_epochs: 5
opt_batch: 128
entropy weight: 0.001
reward scale: 0.001
optimizer: Adam, lr 2.5e-4
The training curve was encouraging. The reward curve moved upward over time, and the policy did not immediately collapse into always folding or always raising. It kept using folds, calls, and multiple raise sizes. That was the first point where the project felt less like a pile of supervised models and more like an actual agent.
Here’s the PPO reward curve over 250 epochs. Each raw point is the average true reward from one PPO training batch over 8,096 simulated environments against frozen opponents.
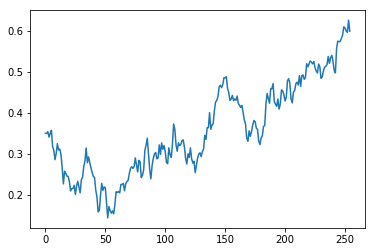
(Reference: poker-ml/Actor Advantage Critic with Proximal Policy Optimization.ipynb)
Optimizing PPO
PPO is a remarkably simple algorithm to implement, especially compared to the TRPO which preceeded it. The main challenge is optimizing the stack enough that we can do enough rollouts to matter.
The first issue we encounter is that running a forward pass for every opponent inside thousands of simulated poker hands becomes expensive very quickly. Worse, each environment is asynchronous: one table might need the hero to act, while another is waiting for three opponent decisions, while another is already over. If we do forward passes synchronously, the batch size is always one, and the throughput is awful.
The solution is to write a batching layer. Each environment requests decisions from a shared BatchedDecisionMaker, which waits until it has accumulated enough requests, and then runs a single batched forward pass, and pushes the responses back. This is tremendously more efficient.
The vast majority of decisions in poker are before the flop, and there’s enough duplication here that we can cache (e.g. if the opponent has 72o under the gun, they can play a cached fold decision without doing a forward pass).
At this point I also had to write my own poker engine, which was much faster than the one I was using previously. This allows optimizations like returning the precise expectancy after players go all-in (e.g. 57% equity), instead of winning either 0% or 100% based on (un)lucky draws.
Playing For Real
Well, after training all this stuff, I’m definitely going to play!
This stage was actually quite involved. I had to spin up a windows VM, download some sketchy windows-only poker clients from offshore companies, and then transfer some cryptocurrency into my account.
I then wrote a screen scraper and mouse-mover/clicker, which would parse recent actions from the screen, decide on an appropriate action, and click the call/raise button. The screen scraping was actually most of the latency here; inference was quite fast. And the mouse has to jiggle as it moves, otherwise you get banned!
This never got to the level of stability where I could leave it alone for hours. There are all kinds of situations which would trip up the screen scraper and require manual intervention, including e.g. multiway shoves, going bust, etc, so I typically stuck around and babysat it.
How did the agent do? It lost approximately ten buy-ins over several hours of play, so quite poorly, despite strong performance in the training environment. What happened?
My best hypothesis is that the approximation of the player pool was correct on average. But poker returns are driven by the tails, and I suspect that the simulations of other players were imperfect in tail outcomes and unusual situations. So there are plenty of degenerate strategies which the proximal policy optimizer can discover, which profit tremendously in the training environment, but exploit failures to faithfully approximate player behavior instead of true player pool tendencies.
I probably could have closed the loop here, by e.g. upsampling situations in the typical player policy models with high loss, but by this point I had been working on the project for 8 months and was ready to stop.
Notes
[0] One of the kaggle metas at this time was to pretrain on large datasets (often external to the competition). In retrospect, pretraining on external data was obviously quite prescient.
Our overall strategy, then, is to build up rich representations of poker, players, etc., and then at the end fine-tune a PPO agent exploiting those representations. We hope, by using this strategy, to minimize the amount of compute required for the eventual reinforcement learning.